Read Raw Text Information from Excel Files
Hauke Sonnenberg
2020-01-10
Source:vignettes/tutorial.Rmd
tutorial.RmdThis package provides functions to read spreadsheet data from Microsoft Excel files. To achieve this, it uses functions from the package readxl.
In contrast to the default behaviour of the readxl functions, this package reads the raw text information from spreadsheets. No type conversions are performed. Being all of the same type (character) the text values are returned in a matrix and not in a data frame as it is the case for the readxl package.
Also, when using this package, all values keep their original position. By default, the readxl-functions remove empty rows at the beginning of a sheet. This leads to row numbers in the returned data frame that do not correspond to the original row numbers in the Excel sheet. For validation purposes, I prefer that all values appear at the same positions in the returned matrix as they have in the sheet. This is what this package does.
Reading Table Data from a Spreadsheet Program
MS Excel is a spreadsheet program. It does not “know” where a table starts and where it ends and it does not clearly assign a type to a column. Instead, each cell can have its own type so that there can be cells of different types in the same column. However, functions such as readxl::read_excel() try to communicate with Excel as if it was a database management system. For each column, the values in the first few rows of the column are inspected and based on the found type the whole column is then converted accordingly. This may lead to conversion errors, e.g. if the first few values look numeric but further values cannot be interpreted as numeric, such as ">1000". In these cases the readxl functions return a data frame in which the text values are removed, i.e. set to NA. This package avoids these data losses as it keeps the original (text) information and lets the user decide what to do.
Read MS spreadsheet with readxl
We demonstrate this behaviour by reading a sheet from an example Excel file. The top and bottom parts of the “table” look as follows:
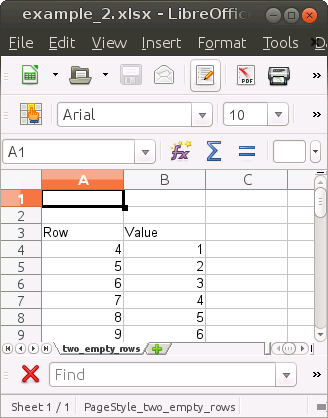
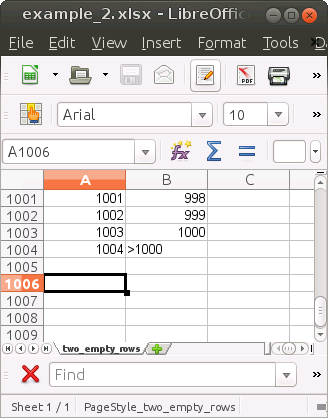
We first read this sheet with the read_excel() function from the readxl package:
# Path to example Excel file
file <- system.file("extdata/example_2.xlsx", package = "kwb.readxl")
# Read the first sheet with readxl::read_excel
data <- readxl::read_excel(file)
#> Warning in read_fun(path = enc2native(normalizePath(path)), sheet_i = sheet, :
#> Expecting numeric in B1004 / R1004C2: got '>1000'
# The first empty rows were skipped and both columns are numeric (double)
head(data)
#> # A tibble: 6 x 2
#> Row Value
#> <dbl> <dbl>
#> 1 4 1
#> 2 5 2
#> 3 6 3
#> 4 7 4
#> 5 8 5
#> 6 9 6As described above, the two empty rows on top were skipped. Also, column B was assumed to be numeric (double <dbl>) even though it contains a text value in row 1004 (see image above).
Read sheet with kwb.readxl
Now we read the same spreadsheet with get_raw_text_from_xlsx() from this package:
# Read the sheet into a list of character matrices
sheets <- kwb.readxl::get_raw_text_from_xlsx(file, sheets = "two_empty_rows")
#>
#> File: 'example_2.xlsx'
#> Folder: '/home/travis/R/Library/kwb.readxl/extdata'
#> Reading sheet 'two_empty_rows' as raw text ...
#> ok. (0.01s)
# Show the first rows of the first matrix
head(sheets$sheet_01)
#> col_01 col_02
#> [1,] NA NA
#> [2,] NA NA
#> [3,] "Row" "Value"
#> [4,] "4" "1"
#> [5,] "5" "2"
#> [6,] "6" "3"
# Show the last rows of the first matrix
tail(sheets$sheet_01)
#> col_01 col_02
#> [999,] "999" "996"
#> [1000,] "1000" "997"
#> [1001,] "1001" "998"
#> [1002,] "1002" "999"
#> [1003,] "1003" "1000"
#> [1004,] "1004" ">1000"The first two empty rows are kept so that the row number in the returned matrix corresponds to the row number in the Excel file. This is helpful if we want to warn the user about possible problems, such as the non-numeric value in row 1004:
# Store the text matrix in sheet
sheet <- sheets$sheet_01
# Get the number of the row containing a non-numeric value in column 2
invalid_row <- max(which(is.na(as.numeric(sheet[, 2]))))
#> Warning in which(is.na(as.numeric(sheet[, 2]))): NAs introduced by coercion
# Give a message to the user
cat("Dear user, please have a look at row", invalid_row, "of the sheet")
#> Dear user, please have a look at row 1004 of the sheet